Нейрокомпьютинг и его применения в экономике и бизнесе
Индивидуальная нормировка данных
Приведение данных к единичному масштабу обеспечивается нормировкой каждой переменной на диапазон разброса ее значений. В простейшем варианте это - линейное преобразование:

в единичный отрезок:


Линейная нормировка оптимальна, когда значения переменной


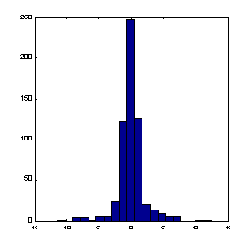
Рис. 7.2. Гистограмма значений переменной при наличии редких, но больших по амплитуде отклонений от среднего
Гораздо надежнее, поэтому, ориентироваться при нормировке не на экстремальные значения, а на типичные, т.е. статистические характеристики данных, такие как среднее и дисперсия:



В этом случае основная масса данных будет иметь единичный масштаб, т.е. типичные значения всех переменных будут сравнимы (см. рисунок 7.2).
Однако, теперь нормированные величины не принадлежат гарантированно единичному интервалу, более того, максимальный разброс значений

Линейное преобразование, как мы убедились, неспособно отнормировать основную массу данных и одновременно ограничить диапазон возможных значений этих данных. Естественный выход из этой ситуации - использовать для предобработки данных функцию активации тех же нейронов. Например, нелинейное преобразование


нормирует основную массу данных одновременно гарантируя, что

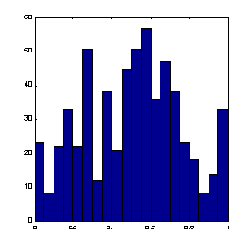
Рис. 7.3. Нелинейная нормировка, использующая логистическую функцию активации

Как видно из приведенного выше рисунка, распределение значений после такого нелинейного преобразования гораздо ближе к равномерному.
До сих пор мы старались максимизировать энтропию каждого входа (выхода) по отдельности. Но, вообще говоря, можно добиться гораздо большего максимизируя их совместную энтропию. Рассмотрим эту технику на примере совместной нормировки входов, подразумевая, что с таким же успехом ее можно применять и для выходов а также для всей совокупности входов-выходов.